
As I mentioned yesterday in the community forum, Trados Studio is currently VERY poor at analyzing matches between alphanumeric elements. It actually seems to consider ANY combination of letter(s) and number(s) as equivalent to ANY other.
For instance, I had Qs&As to translate, with countless cases of A1., A2., A3., etc., to be translated to R1., R2., R3., etc.
In the applicable translation memory, I already had the following matches, which were the ones required in context (for English to French translation):
• Q1. => Q1.
• A1. => R1.
Nevertheless, here is what Trados suggested me as “matches”: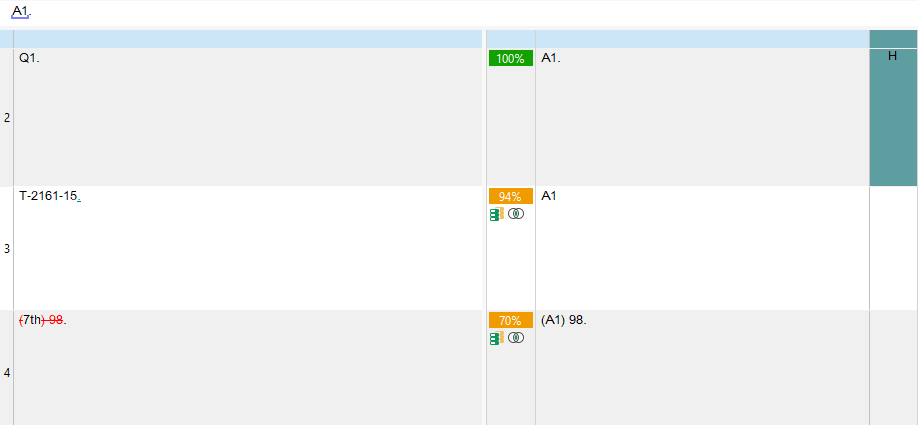
Worse than that, even though the R1., R2., R3... all the way to R14. were already confirmed and in the memory, EVERY TIME I confirmed a Q1., Q2. or else, ALL my confirmed R's reverted back to A's.
• First, I don't understand why “R1.” would not even appear in the match list, while it was ALREADY in the memory AND 100% equivalent.
• Second, “Q1.” should definitely not be shown as a 100% equivalent, as reflected by the fact that the suggested translation “match” is not the right one.
• Third, but not least, the ONLY logic behind considering “T-2161-15” and “(7th) 98” as matches for “Q1.” or “A1.” seems to be as dumb as “they all are alphanumeric is some way”. Not very promising with regards to possible results...
As a test, I deleted the confirmed “Q1. => Q1.” segment from the memory, and ONLY THEN did the existing “A1. => R1.” segment appear is the matches. Then I re-added the “Q1. => Q1.” segment, and the recognition worked properly. But still, the problem should never have occurred in the first place... and Trados should definitely NOT have considered “(7th) 98” as a match for “A1.” considering that its suggested translation ended up as “(A1) 98.” instead of “R1.”

Top Comments