

Following my latest update on the DD4T and DXA merge, lets take a look at the new architecture we have in mind for DXA 2.0. But first maybe I should explain why we think there is a need for a new architecture. Following the manifesto of the new framework there are a lot of things we need to focus on. Taking the following four statements from the manifesto: "easy, supportable, performing and scalable", we have a huge challenge around the current architecture. The high level design as discussed during the 2016 MVP retreat, suggest using RESTful content from the source, which isn't yet available in Web 8. The code duplication in Java and .NET we have in the frameworks are not helping us either. Adding to that the request for client-side (JavaScript) framework, and single-page application support, it makes sense we look at changing the architecture.
Architecture vision
The new architecture should be clean (easy to understand and explain), and support the highest performance possible. This means we need to think about executing the right tasks at the right place in the framework. The picture below shows the envisioned architecture which separates tasks and adds possible support for client-side (JavaScript) frameworks, and single-page applications. It introduces a DXA Model Service which we plan to make part of the SDL Web Content Delivery (micro) services.
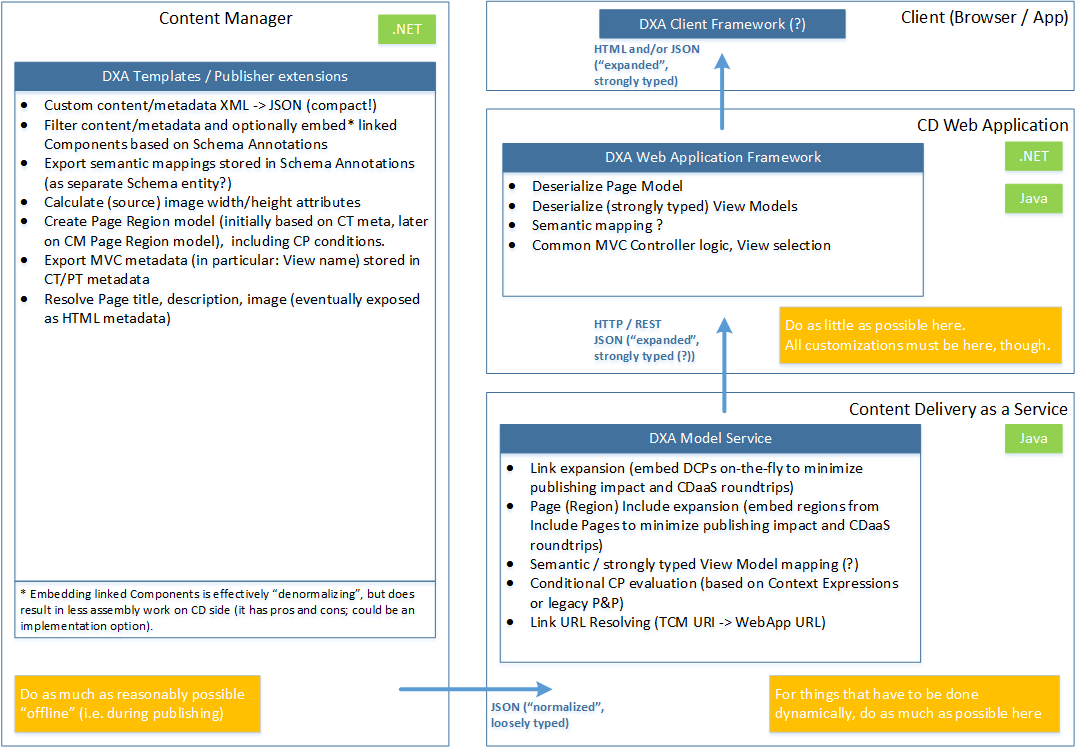
The DXA Model Service can significantly increase performance by reducing the number of round-trips needed by the web application to the SDL Web Content Delivery Datastore. Considering it will eventually become part of the SDL Web public Content Services, it makes sense to write it only in Java, reducing the code duplication in a complex part of the framework. We therefore expect this part of the framework to not be customizable, and hence we need to add the ability to customize the output of this in the web application itself (shown as Model Mapping' in the next picture). It will remain open source however, since it is important to have insight into the model mapping logic through source code access.
The model service (either through a Web Application or accessed directly) will also allow for creation of a DXA Client Framework, which enables client-side (JavaScript) framework, and single-page application support. Because the earliest option for adding such a model service into SDL Web Content Delivery would be SDL Web 9, we need to start with an in-between scenario, which will be possible on SDL Web 8 directly, and makes the adoption of this model service by SDL Web less critical. This will bring us the following architecture evolution:
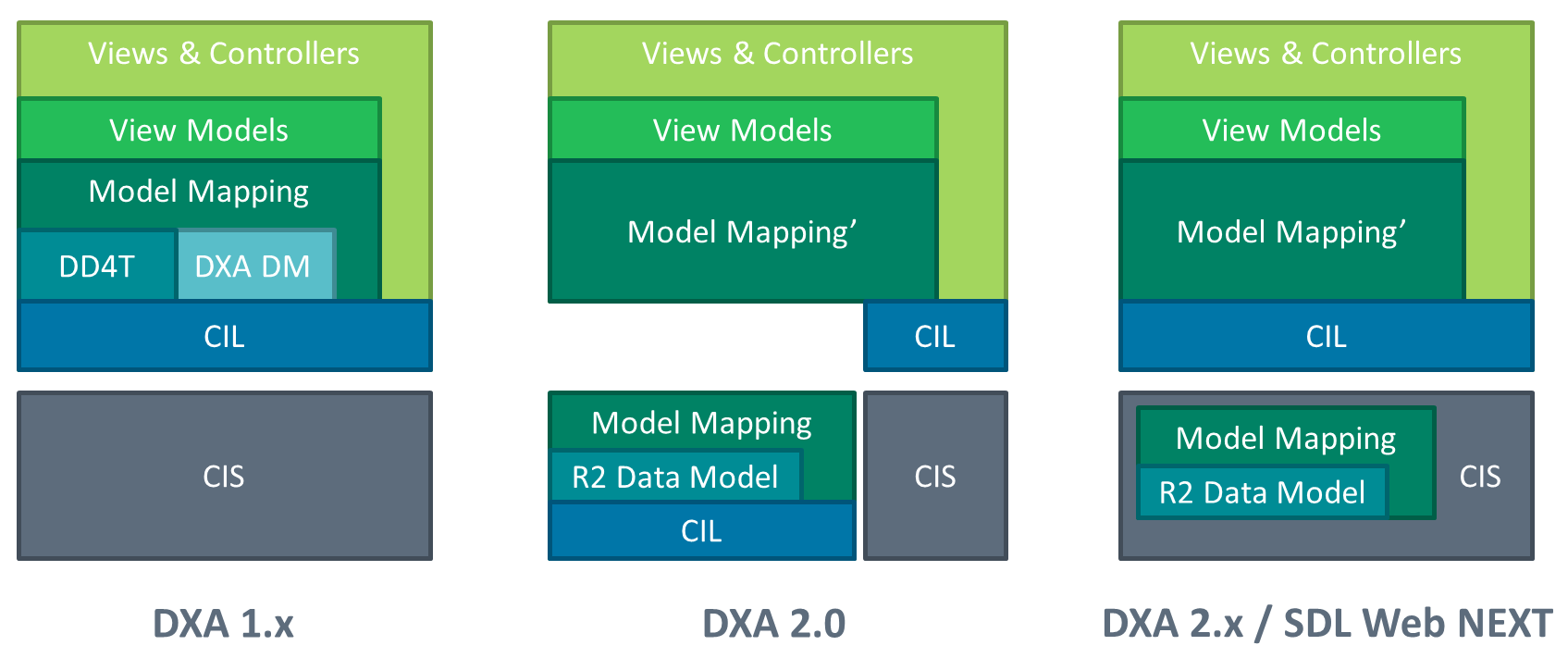
- DXA 1.x - current DXA architecture with DD4T for SDL Web 8
- DXA 2.0 - introduction of a DXA Model Service installed as part of a CIS environment
- DXA 2.x / SDL Web NEXT - Model service as part of the public Content API
As described in the architecture vision picture, the model service will be RESTful Web service. The DD4T datamodel and DXA domain model (with semantic mapping support) is replaced by the R2 data model.
R2 data model
The DD4T data model is extremely verbose and contains a lot of unnecessary data (which made sense in its original purpose to do all rendering on CD-side instead of CM-side, but for DXA 2.0 we don't need all that data and we already know the Schemas/types out-of-band).
In general, the DD4T data model is much closer to the TCM domain model than to a strongly typed View Model we need, forcing us to do mapping logic on CD-side (at request time) which could have been done on CM-side (at publish time, so "offline"). Hence came the idea to define our own data model which is more abstract and much closer to the strongly typed View Models (maybe even re-using the top of the View Model hierarchy), making the mapping from the new data model to View Models much more straight-forward. Semantic mapping remains functionally, but should be refactored to work with this R2 data model as input (and simplified; current semantic mapping code is unnecessarily complex).
On the other hand, we should still support the DD4T/DXA 1.x data model for backwards compatibility with DXA 1.x implementations (allowing gradual migration to the new R2 data model) and to facilitate migrations from DD4T implementations.
Data model normalization
Another problem with the way that DD4T Data Models are created is that Component Links and Keyword Links are expanded in a course-grained manner: all Component and Keywords Links are expanded n Levels deep (expandLinkDepth parameter on TBBs). This results in potentially huge Pages / DCPs containing information that may not be needed at all for the View Model mapping. This has significant performance impact on CM-side rendering, transporting, deploying and retrieving. Furthermore, this de-normalization means that Components may get included in many Pages / DCPs, meaning that many items may have to be republished when a Component is changed in CM.
We should support a fully normalized data model where each Component has its own DCP (which reflects only the Component's Data, earlier this concept has been referred to as Data Presentation) and Component and Keyword Links are expanded on CD-side (as part of the DXA Model Mapping) if needed.
We should also support selective Component/Keyword Link expansion (based on Schema Annotations and/or CT metadata). In a similar fashion we will treat Include Page expansion, so include pages will really become regions and their contents expanded dynamically. This way published content will no longer include DCPs or other linked content from the CM. Furthermore, the model service can be optimized for the environment it is delivering data for, so on staging environments, it can include XPM metadata, while for live that is excluded.
