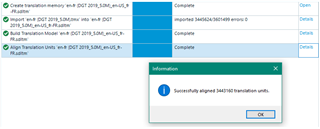
Is there a limitation on or recommendation about the size of your TM? I have not been able to use a 14GB TM with a 2.5 million TUs because it will cause Studio to crash. Yes, I waited several hours and retried several times until it was upgraded. No, it didn't happen before Studio 2019 (although the TM was smaller back then).